
티스토리 뷰
문제 가설
매우 크고 복잡한 JSON 데이터가 있다고 하고, 이 JSON 데이터 중에서 필요한 것은 전체 데이터 크기에 비해 작다고 해봅시다.
이 경우 전체 JSON 문자열을 JSON 데이터로 파싱한 후, 데이터를 탐색하는 것은 계산자원 낭비가 있습니다.
왜냐하면, 메모리가 어떻게 사용되는지 생각해보면,
- JSON 문자열을 메모리 공간으로 불러오고
- JSON 문자열을 읽으면서, 파싱하면서 해당하는 JSON 값을 생성합니다. (동적 메모리 할당)
그럼 JSON 문자열 + 생성된 JSON 구조만큼의 메모리를 써야합니다.
게다가 실행 중에 동적 메모리 할당이 일어나서 성능에 좋지 않습니다. (동적 할당은 아주 비쌉니다)
요즘엔 비동기 구현이 널리 사용되면서 한 프로세스의 메모리 공간(가상 메모리)을 공유하는 경우가 많습니다.
메모리 할당/해제로 인한 성능 병목이 일어날 가능성이 큽니다.
만약 JSON 구조가 복잡하다면, 데이터 탐색 과정에서도 Cache Miss으로 인한 성능 저하가 생길 수도 있습니다.
이 문제를 해결하기 위해 문자열을 파싱하며
필요한 데이터만 메모리에 할당하는 테크닉을 찾아봅시다.
Serde
Rust의 Serde 라이브러리는 Custom Parsing (Deserializing) 기능을 지원합니다.
이 기능을 이용해서 전체 JSON 문자열 중에서 원하는 부분만 데이터로 가져오는 구현이 가능합니다.
- Array of values without buffering · Serde
- (2) Memory-efficient parsing of a large amount of JSON data : rust (reddit.com)
위 두 글에서는 전체 배열 중에서 가장 큰 값을 계산하는 상황을 가정합니다.
단순한 방법(Naive, Whole Parsing)은 JSON 문자열을 모두 파싱한다음, 배열에서 가장 큰 값을 가져오는 방법입니다.
그러면 위에서 말한 문제가 발생합니다.
위에서 말했던 문제를 피하기 위해서, Serde의 튜토리얼 코드를 이용해 봅시다.
모든 값을 저장한 뒤, 가장 큰 값을 찾는 것이 아니라
JSON 문자열 자체를 읽어들이면서 가장 큰 값만 저장합니다.
실험
Serde 가이드의 코드를 이용해 얼마나 성능 향상을 이룰 수 있는지 확인해봅시다.
- 실행 코드: json_faster/main.rs at main · bonjune/json_faster · GitHub
- 바이너리 실행당 1000 번씩 파싱 실행
- 테스트 코드: bonjune/json_faster/perf_test.py (github.com)
- 바이너리를 10 번씩 실행
- 1000회 실행 샘플을 10번 측정한다.
Test RELEASE build...
size = 10, iterated 10 times for 1000-iterated avg measurement
custom parser = 829.4104
whole parser = 2314.9652
size = 100, iterated 10 times for 1000-iterated avg measurement
custom parser = 5695.696500000001
whole parser = 7024.5271999999995
size = 1000, iterated 10 times for 1000-iterated avg measurement
custom parser = 38663.4973
whole parser = 43122.097499999996
size = 5000, iterated 10 times for 1000-iterated avg measurement
custom parser = 173172.5377
whole parser = 287390.61539999995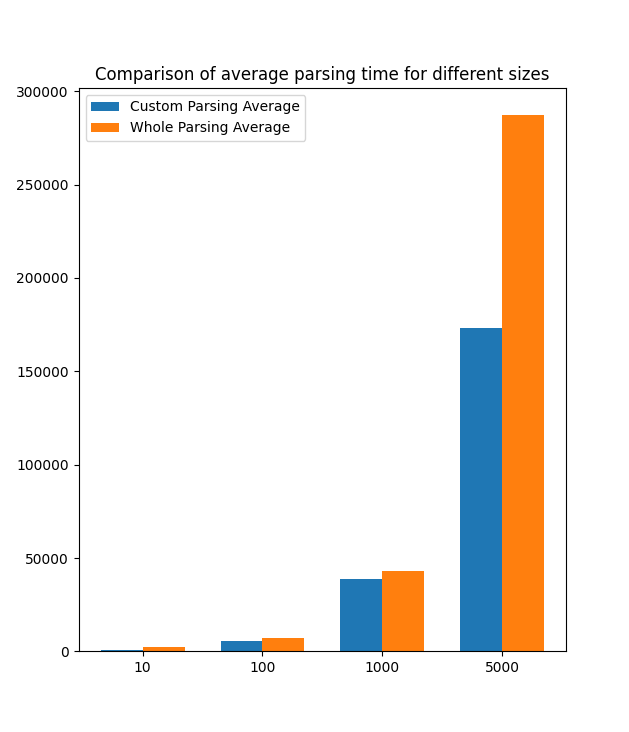
| JSON 크기 | Custom Parsing | Naive (Whole) Parsing | Ratio (Whole / Custom) |
| 10 | 829.4104 | 2314.9652 | 2.790 (whole/custom) |
| 100 | 5695.6965 | 7024.5272 | 1.233 (whole/custom) |
| 1000 | 38663.4973 | 43122.0975 | 1.115 (whole/custom) |
| 5000 | 173172.5377 | 287390.6154 | 1.659 (whole/custom) |
작은 JSON 크기 (10)일 때는 2.8배에서, 큰 JSON 크기 (5000)에서는 1.66배 성능 향상이 있습니다.
의문점들
- JSON 크기가 늘어나면서 두 성능 향상 비율이 줄었다가 늘어납니다 (?)
- JSON 크기가 작은 경우는, 사실 메모리 병목이 크지 않았을거라 예상했기 때문에 큰 차이가 나지 않을 것 같았는데 2.8배나 차이가 나서 의외였습니다.
- 메모리 할당 이외에 성능 차이가 나는 이유가 무엇이 있을까요?
- 실제로 메모리 할당이 어떻게 일어나고 있을까요?
- 같은 사이즈의 데이터에 대해서 Whole Parsing, Custom Parsing을 모두 같은 프로세스에서 진행했기 때문에 두 측정값에 불필요한 Correlation이 있을 수도 있습니다.
- 과연 Custom Parsing에 사용된 Visitor는 무엇일까요?
일단 프로세스를 분리해서 Correlation을 줄여보도록 하겠습니다.

| JSON 크기 | Custom Parsing | Naive (Whole) Parsing | Ratio (Whole / custom) |
| 10 | 869.0643 | 1789.4198 | 2.059 (whole/custom) |
| 100 | 5757.8599 | 6382.1124 | 1.108 (whole/custom) |
| 1000 | 37910.4228 | 42294.4277 | 1.116 (whole/custom) |
| 5000 | 173925.0794 | 282953.0509 | 1.627 (whole/custom) |
큰 데이터셋에서는 그렇다 할 차이가 나지는 않네요.
같은/다른 프로세스에서 측정하더라도 크게 달라지는 것은 없습니다.
Takeaways and more
- 모든 데이터를 메모리에 올리지 않고 분석할 수 있는 방법이 있다.
- 중간 사이즈 데이터에 대해서는 1.1배, 큰 사이즈 데이터에 대해서는 1.6배의 성능 향상이 있다.
- 러스트 바이너리의 메모리 사용량 측정방법에 대해 공부가 필요하다. (프로파일링?)
- 플랫폼마다 다를텐데 깜깜..
- 실제로 메모리 할당이 성능에 영향을 미치고 있는지는 어떻게 검사할까?
- 러스트 바이너리의 성능을 측정할 수 있는 정확한 방법은 무엇일까?
- 컴파일러 최적화를 피하는 방법
- 프로세스 간 Correlation을 줄이는 방법
- Serde의 내부 구현에 대해 공부해보자: Decrusting the serde crate - YouTube
'컴퓨터' 카테고리의 다른 글
| Python 개체 설계의 유연함 (0) | 2023.05.08 |
|---|---|
| 프림 알고리즘 (Prim's Algorithm, Minimum Spanning Tree) (4) | 2023.05.08 |
| KAIST CS348 정보보호개론: mini-RSA 구현 최적화 과정 (1) | 2023.05.01 |
| 온라인 컴퓨터 사이언스 기초 강의들 (1) | 2023.04.25 |
| Python 함수의 기본값의 비밀 (1) | 2023.04.25 |
- Total
- Today
- Yesterday