
티스토리 뷰
.NET에서 프로그램을 작성하다보면 Stream(스트림)을 사용할 때가 많은데, 공식 문서를 읽어보면 이렇게 쓰여있다.
Stream is the abstract base class of all streams. A stream is an abstraction of a sequence of bytes, such as a file, an input/output device, an inter-process communication pipe, or a TCP/IP socket. The Stream class and its derived classes provide a generic view of these different types of input and output, and isolate the programmer from the specific details of the operating system and the underlying devices.
Streams involve three fundamental operations:
You can read from streams. Reading is the transfer of data from a stream into a data structure, such as an array of bytes.
You can write to streams. Writing is the transfer of data from a data structure into a stream.
Streams can support seeking. Seeking refers to querying and modifying the current position within a stream. Seek capability depends on the kind of backing store a stream has. For example, network streams have no unified concept of a current position, and therefore typically do not support seeking.Some of the more commonly used streams that inherit from Stream are FileStream, and MemoryStream.
I/O나 프로세스간 파이프, 네트워크 소켓 등을 추상화하는 클래스라고 소개되어 있는데, 개념적으로 비교해보면 리눅스의 fd (File Descriptor) 같은 개념이다. 리눅스에서도 I/O, 파이프, 소켓을 모두 fd로 표현하기 때문이다. 리눅스 시스템 프로그래밍의 fd와 다른 점은 FileStream, MemoryStream처럼 용도에 맞게 특수화된 기능을 제공하고 C#, F#의 타입시스템을 사용할 수 있다는 점인 것 같다.
검증해보고 싶은 생각이 있다. 만약 정말 스트림이 fd와 같은 추상화를 제공한다면, 어플리케이션 레벨에서의 쓸데없는 일을 줄이면 프로그램이 더 효율적으로 작동해야 한다. 간단하게, 파일을 복사하는 프로그램을 작성해보자. 첫번째 프로그램은 기존의 파일을 읽어 문자열로 받아들인 후, 그 문자열을 다른 파일에 쓰게 할 것이다. 그리고 두번째 프로그램은 기존의 파일을 스트림으로 열고, 다른 파일의 스트림에 복사하도록 할 것이다. 만약 스트림의 내부구조가 잘 작성되어 있다면, 두번째 프로그램은 어플리케이션 단계에서 쓸데없는 메모리 복사 연산을 하지 않으므로 더 효율적으로 동작해야 한다.
F#으로 간단한 프로그램을 작성해보자.
open System
open System.IO
open System.Diagnostics
let slowCopy () =
let lyric = File.ReadAllText ("./billiejean.txt")
File.WriteAllText ("./billiejean2.txt", lyric)
let fastCopy () =
use lyric = new FileStream ("./billiejean.txt", FileMode.Open)
use f = new FileStream ("./billiejean3.txt", FileMode.CreateNew)
lyric.CopyTo (f)
let sw = Stopwatch ()
sw.Start ()
slowCopy ()
sw.Stop ()
let slowCopyTicks = sw.ElapsedTicks
printfn "slowCopy ticks = %d" slowCopyTicks
File.Delete ("./billiejean3.txt")
sw.Restart ()
fastCopy ()
sw.Stop ()
let fastCopyTicks = sw.ElapsedTicks
printfn "fastCopy ticks = %d" fastCopyTicks
printfn "slowCopyTicks / fastCopyTicks = %f" (float slowCopyTicks / float fastCopyTicks)실행 결과는 다음과 같다.
$ dotnet run
slowCopy ticks = 10383228
fastCopy ticks = 922610
slowCopyTicks / fastCopyTicks = 11.254190
$ dotnet run
slowCopy ticks = 10762362
fastCopy ticks = 959818
slowCopyTicks / fastCopyTicks = 11.212920
가설이 맞았다. 대략 10~12배의 속도 차이가 간다. 이런 차이가 나는 이유는 보통 다음과 같은 과정이 일어나기 때문이다.
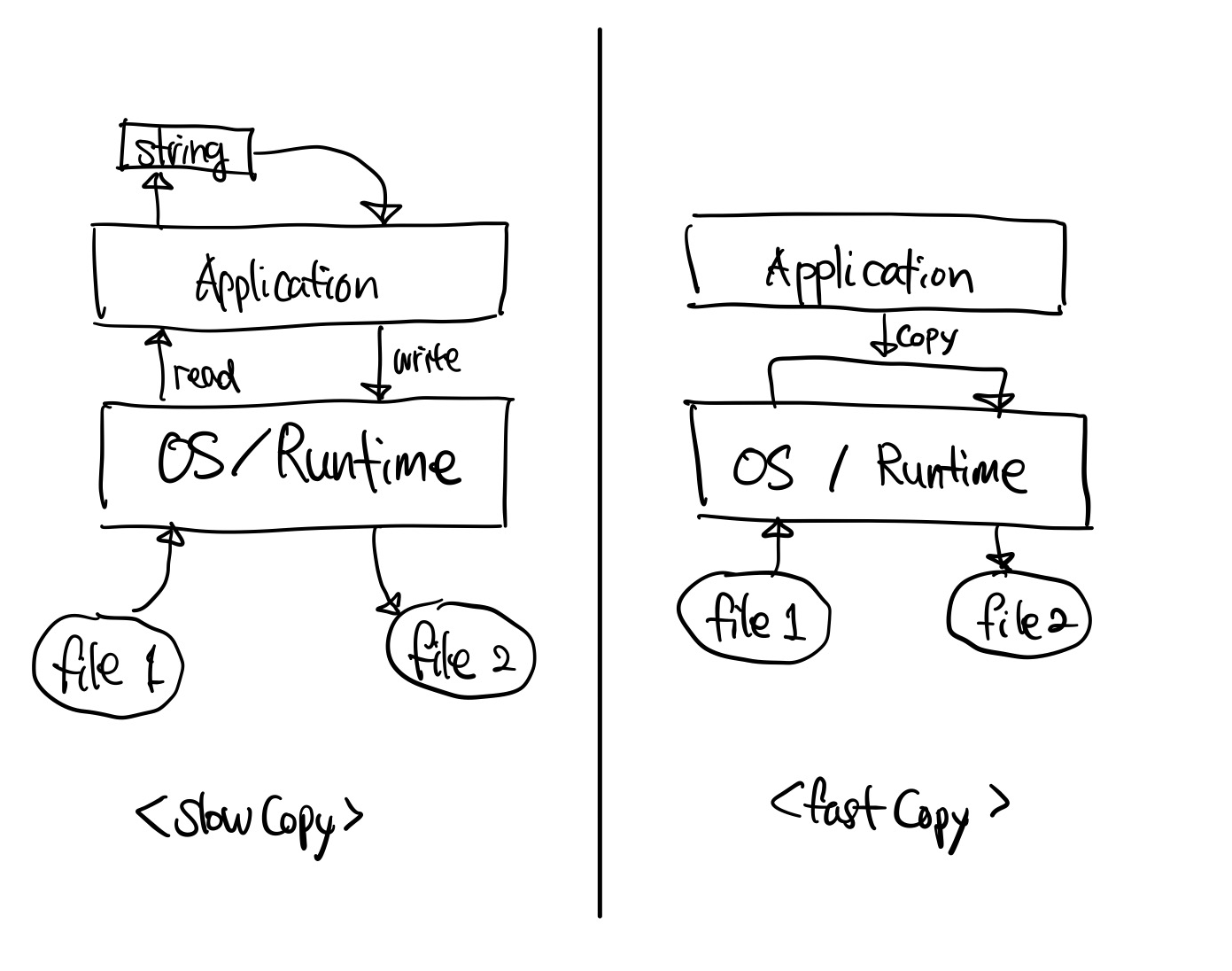
slowCopy는 원본 파일의 내용을 문자열로 어플리케이션 레벨에 할당해 저장한 뒤에 문자열을 대상 파일에 쓴다. 이 과정에서 어플리케이션 레벨에 불필요한 메모리 할당이 일어나고, 어플리케이션과 OS 사이의 시스템콜이 여러번 일어나거나 OS 단계 (혹은 런타임)에서 버퍼링이 발생한다. 시스템콜은 아주 비싸기 때문에, 이런 식의 접근은 피해야 한다. fastCopy에서는 어플리케이션 레벨에 메모리를 할당해 원본 파일의 내용을 저장하지 않고, OS/런타임에게 복사를 요청한다. 데이터가 OS단계에서 파일에서 파일로 바로 이동하기 때문에 효율적인 구현이 가능하다.
public static string ReadAllText(string path)
=> ReadAllText(path, Encoding.UTF8);
public static string ReadAllText(string path, Encoding encoding)
{
Validate(path, encoding);
using StreamReader sr = new StreamReader(path, encoding, detectEncodingFromByteOrderMarks: true);
return sr.ReadToEnd();
}
public void CopyTo(Stream destination) => CopyTo(destination, GetCopyBufferSize());
public virtual void CopyTo(Stream destination, int bufferSize)
{
ValidateCopyToArguments(destination, bufferSize);
if (!CanRead)
{
if (CanWrite)
{
ThrowHelper.ThrowNotSupportedException_UnreadableStream();
}
ThrowHelper.ThrowObjectDisposedException_StreamClosed(GetType().Name);
}
byte[] buffer = ArrayPool<byte>.Shared.Rent(bufferSize);
try
{
int bytesRead;
while ((bytesRead = Read(buffer, 0, buffer.Length)) != 0)
{
destination.Write(buffer, 0, bytesRead);
}
}
finally
{
ArrayPool<byte>.Shared.Return(buffer);
}
}함수들이 어떻게 구현되어있나 코드를 읽어보았다. slowCopy의 경우 스트림에서 파일 내용을 읽어 string으로 반환한다. 파일 내용만큼의 메모리 할당이 일어나야한다는 이야기다. 만약 fastCopy가 사용하는 CopyTo의 경우는 ArrayPool에서 bufferSize 만큼의 메모리 공간을 빌려온 다음, 이 버퍼를 이용해 파일 내용을 복사한다 (Read, then Write). 추가적인 메모리 할당이 최소화하고 이미 생성된 메모리를 사용한다는 이야기다. ArrayPool<T> Class (System.Buffers) | Microsoft Learn 를 보면 자주 할당 및 해제되는 메모리의 경우 Pool을 사용하는 것이 유리하다고 나와있다. 당연히 미리 할당된 메모리를 사용하는 것이 더 효율적인 방법이다.
이 내용은 CopyTo 함수에서 호출되는 GetCopyBufferSize () 에서도 이어진다.
private int GetCopyBufferSize()
{
// This value was originally picked to be the largest multiple of 4096 that is still smaller than the large object heap threshold (85K).
// The CopyTo{Async} buffer is short-lived and is likely to be collected at Gen0, and it offers a significant improvement in Copy
// performance. Since then, the base implementations of CopyTo{Async} have been updated to use ArrayPool, which will end up rounding
// this size up to the next power of two (131,072), which will by default be on the large object heap. However, most of the time
// the buffer should be pooled, the LOH threshold is now configurable and thus may be different than 85K, and there are measurable
// benefits to using the larger buffer size. So, for now, this value remains.
const int DefaultCopyBufferSize = 81920;
int bufferSize = DefaultCopyBufferSize;
if (CanSeek)
{
long length = Length;
long position = Position;
if (length <= position) // Handles negative overflows
{
// There are no bytes left in the stream to copy.
// However, because CopyTo{Async} is virtual, we need to
// ensure that any override is still invoked to provide its
// own validation, so we use the smallest legal buffer size here.
bufferSize = 1;
}
else
{
long remaining = length - position;
if (remaining > 0)
{
// In the case of a positive overflow, stick to the default size
bufferSize = (int)Math.Min(bufferSize, remaining);
}
}
}
return bufferSize;
}주석을 읽어보면 오브젝트 힙의 구조와 적절한 버퍼 사이즈에 관련성이 있는 것 같다. Large Object Heap 이라는 게 있는 것 같은데, 버퍼를 이곳에 위치시키기 위한 버퍼 사이즈를 고른다고 한다. 그런데 Pooling이 사용된다는 하는데 ...
.NET의 메모리 구조를 잘 알지 못해서, 아직 정확한 의미를 파악하지 못했다.
세부적인 내용에서 오류가 있을 수 있기 때문에, 잘못된 내용이 있다면 댓글로 남겨주시길 바랍니다.
참고자료
ArrayPool<T> Class (System.Buffers) | Microsoft Learn
copy_file_range(2) - Linux manual page (man7.org)
'컴퓨터' 카테고리의 다른 글
| JSON 역직렬화 성능 최적화 기법 탐구 1 (1) | 2023.05.06 |
|---|---|
| KAIST CS348 정보보호개론: mini-RSA 구현 최적화 과정 (1) | 2023.05.01 |
| 온라인 컴퓨터 사이언스 기초 강의들 (1) | 2023.04.25 |
| Python 함수의 기본값의 비밀 (1) | 2023.04.25 |
| 효율적인 코드 쓰는 법: CPU는 메모리보다 훨씬 빠르다 (0) | 2023.04.21 |
- Total
- Today
- Yesterday